



Eng.Ali Yahya Jirjees Salman
Introduction
Data from a wide variety of sources are required for reservoir simulation. Simulation itself produces large quantities of data. Yet, good data management practices for reservoir simulation data are typically neither well-understood nor widely investigated.
Reservoir simulation is inherently a data-intensive process. It starts with geological models and their properties, and assignment of phase behavior or equation of state data, relative permeability and capillary pressure information and geo-mechanical data. It requires layout of the surface facility network, subsurface configuration of wells, their attributes, pressure and rate limits and other production and optimization constraints. Very often, production history information, hydraulics tables, completion tables and logic for runtime management of wells and surface facilities are needed. Finally, special cases like thermal and fractured reservoir simulations require their own set of additional data.
During simulation, time-stepping information, convergence parameters and well performance data can be logged and analyzed. Results, such as pressures and rates from wells and surface facilities and pressures and saturations from the simulation grid can be monitored and recorded. The state of the simulator can be recorded at specified intervals to enable restart of a run at a later time.
This result in an abundance of data to be analyzed, visualized, summarized, reported and archived. Over the years, many authors have tried to address one aspect or another of this data management problem and many commercial and proprietary simulators have made allowances to simplify users’ work in this area. However, in general, data management has not been a widely investigated aspect of reservoir simulation.
Data management in reservoir simulation enables workflows and collaboration, insures data integrity, security and consistency and expedites access to results. In today’s computing environment, data management is an enabler to meet the growing need for reservoir simulation and to make simulation available to a wider audience of professionals, including many kinds of engineers and geoscientists.
Reservoir Management
The main goal of oil reservoir management is to provide more efficient, cost-effective and environmentally safer production of oil from reservoirs. Implementing effective oil and gas production requires optimized placement of wells in a reservoir. A production management environment involves accurate characterization of the reservoir and management strategies that involve interactions between data, reservoir models, and human evaluation. In this setting, a good understanding and monitoring of changing fluid and rock properties in the reservoir is necessary for the effective design and evaluation of management strategies. Despite technological advances, however, operators still have at best a partial knowledge of critical parameters, such as rock permeability, which govern production rates; as a result, a key problem in production management environments is incorporating geologic uncertainty while maintaining operational flexibility.
Combining numerical reservoir models with geological measurements (obtained from either seismic simulations or sensors embedded in reservoirs that dynamically monitor changes in fluid and rock properties) can aid in the design and implementation of optimal production strategies. In that case, the optimization process involves several steps:
1. Simulate production via reservoir modeling;
2. Detect and track changes in reservoir properties by acquiring seismic data (through field measurements or seismic data simulations);
3. Revise the reservoir model by imaging and inversion of output from seismic data simulations.

As stated earlier, one challenging problem in the overall process is incorporating geological uncertainty. An approach to address this issue is to simulate alternative production strategies (number, type, timing and location of wells) applied to multiple realizations of multiple geo-statistical models. In a typical study, a scientist runs an ensemble of simulations to study the effects of varying oil reservoir properties (e.g. permeability, oil/water ratio, etc.) over a long period of time. This approach is highly data-driven. Choosing the next set of simulations to be performed requires analysis of data from earlier simulations.
Another major problem is the enormity of data volumes to be handled. Large-scale, complex models (several hundreds of thousands of unknowns) often involve multiphase, multicomponent flow, and require the use of distributed and parallel machines. With the help of large PC clusters and high performance parallel computers, even for relatively coarse descriptions of reservoirs, performing series of simulations can lead to very large volumes of output data. Similarly, seismic simulations can generate large amounts of data. For example, downhole geophysical sensors in the field and ocean bottom seismic measurements are episodic to track fluid changes. However, per episode, these involve a large number (e.g. hundreds to thousands) of detectors and large numbers of controlled sources of energy to excite the medium generating waves that probe the reservoir.
These data are collected at various time intervals. Thus, seismic simulators that model typical three-dimensional seismic field data can generate simulation output that is terabytes in size. As a result, traditional simulation approaches are overwhelmed by the vast volumes of data that need to be queried and analyzed.
We can state now a definition of reservoir management process which is the utilization of the available resources (i.e., human, technological and financial)) in order to:
1. Maximize benefits (profits) from a reservoir by optimizing recovery.
2. Minimizing capital investments and operating expenses.
Objectives of Reservoir Management
Data replication is common across reservoir simulation models. Initially, a few base reservoir simulation models were available for a reservoir, e.g., P10, P50, and P90 models. These models are used extensively used to explore and evaluate different field development plans or field management strategies. As a result of exploration or evaluation, many more models are derived from these base reservoir models. A derived reservoir model is usually created in two steps:
1. Copying a base reservoir model.
2. Modifying parameter values in the copy.
Furthermore, the derived models can also be used to derive new models. Data replication poses many challenges to reservoir simulation model management. The first challenge is the efficiency of management. Data replication results in new relationships among models. The new relationships can be created based on data components shared by various models. Managing these relationships results in overhead. For example, additional metadata used to track the relationships must be captured and stored. The second challenge caused by data replication is maintaining data consistency among various reservoir simulation models.
Generally, the more one replicates, the more points of divergence are created and the more one is subject to incorrect behaviors. On the other hand, base reservoir simulation models are regularly updated or calibrated as historical production data of the reservoir become available (the process is called history matching in petroleum engineering). Due to the complexity of a reservoir simulation model, propagating changes in these base models properly and efficiently is nontrivial.
So we can summarize the objectives for managing the reservoir in the following points:
– Decrease risk.
– Increase oil and gas production.
– Increase oil and gas reserves.
– Minimize capital expenditures.
– Minimize operating costs.
– Maximize recovery.
– Identify and define all individual reservoirs in a particular field and their physical properties.
– Deduce past and predict future reservoir performance.
– Minimize drilling of unnecessary wells.
– Define and modify (if necessary) wellbore and surface systems.
– Initiate operating controls at the proper time.
– Consider all pertinent economic and legal factors.
Why and when should reservoir management be used?
The ideal time to start managing a reservoir is at its discovery, because:
- Early initiation provides a better monitoring and evaluation tool,
- Costs less in the long run.
A good example of that can be an extra log or an additional hour’s time on a DST may provide better information than could be obtained from more expensive core analysis. It is possible to do some early tests that can indicate the size of a reservoir. If it is of limited size, drilling of unnecessary wells can be prevented.
The magnitude of the investments associated with developing oil and gas assets motivates the consideration of methods and techniques that can minimize these outlays and improve the overall economic value. For several decades, industry practices have attempted to address this issue by considering a variety of approaches that can be referred to collectively as traditional methods. These methods include trial-and-error approaches that conduct a series of “what if” analyses or case studies as well as heuristic and intuition-based efforts that impose rules and learning on the basis of experience or analogies. In contrast, mathematical-optimization techniques can provide an efficient methodology toward achieving these goals by combining all the traditional approaches into a comprehensive and systematic process.
We can overview a case history that shows the effect on production targets between the use of reservoir management and without it.
The case includes the development of a regional complex of gas reservoirs similar to those found in the Gulf of Mexico, the southern gas basin of the North Sea, West Africa, and in basins in the Far East is examined. The example in this paper is an amalgamation of the fields typically developed around the world.
The complex to be developed consists of three main fields with at least one additional satellite. It is assumed that several development decisions have already been made when this work commences. For example, the gas in place for each reservoir; the size, configuration, and number of platforms; and the pipeline infrastructure have been determined or specified. The layout of the reservoirs and infrastructure is shown below.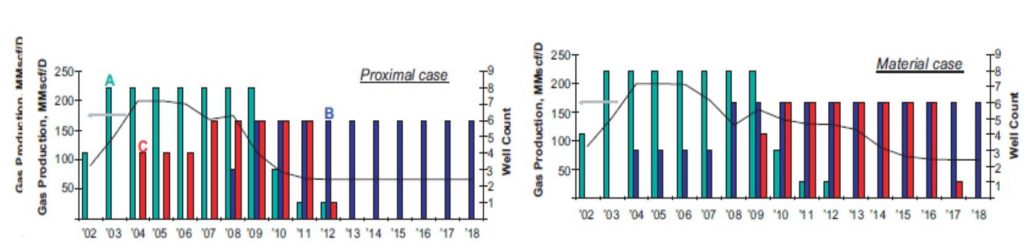

The Reservoir A platform has eight well slots, with each well costing U.S. $15 million. Sand production and water coning place flow limitations on the different wells, ranging from 10 to 25 MMscf/D. Water influxes occurs in Reservoir A, although the relatively high production rates limit the support to approximately 100 psi for the period of interest. Flow limitations for wells in Reservoirs B and C are comparable to wells in Reservoir A, although Reservoir B does contain one well that can produce up to 30 MMscf/D. The total gas handling capacity at the terminal is 200 MMscf/D, and the gas must be delivered at a pressure of at least 900 psi.And here is a schematic graphs show the great difference in producing the different cases with the use of reservoir management and without.
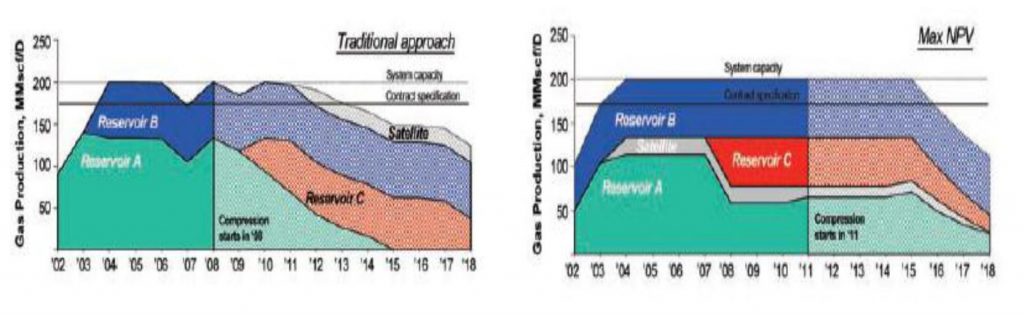

The highly nonlinear nature of the physical system and the combinatorial complexity of development decisions warrant the proper modeling of the assets, the appropriate formulation of the optimization systems, and the use of tailored state-of-the-art mathematical techniques to render these numerical systems tractable. However, the considerable economic benefits, as demonstrated in this paper, provide the motivation for use of these techniques. Because most of the capital-investment commitments are made in the early life of an asset, a narrow window of opportunity exists to influence the economic performance of the asset. Thus, there is a clear need to apply such technology at the earliest opportunity.


Reservoir Management Team Involved
Reservoir management process should be through a team approach in order to:
– Facilitate communication among various engineering disciplines, geology, and operations.
– The engineer must develop the geologist’s knowledge of rock characteristics and depositional environment, and a geologist must cultivate knowledge in well completion and other engineering tasks, as they relate to the project at hand.
– Each member should subordinate their ambitions and egos to the goals of the reservoir management team.
– Each team member must maintain a high level of technical competence.
– Reservoir engineers should not wait on geologists to complete their work and then start the reservoir engineering work. Rather, a constant interaction between the functional groups should take place.
The reservoir management team should include the following elements at any company:
1. Management.
2. Geology and geophysics.
3. Reservoir engineering.
4. Economics and finance.
5. Drilling engineering.
6. Design and construction engineering.
7. Production and operation engineering.
8. Gas and chemical engineering.
9. Research and development.
10. Environment.
11. Legal and landlords.
11. Services provider.
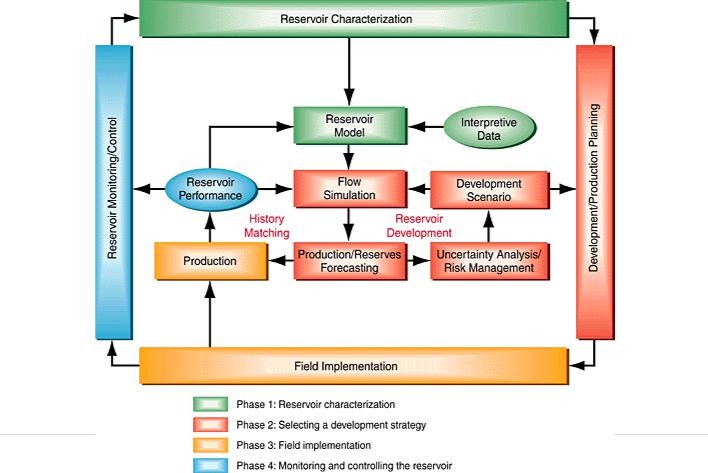
Reservoir Management Process
The process of managing the reservoir includes:
- Setting strategy (goals): The key elements for setting the reservoir management goals are:
- Reservoir characteristics.
- Total environment.
- Available data.
- Developing a plan:
- Development and depletion strategy
- Environmental consideration.
- Data acquisition and analysis.
- Geological & numerical model studies
- Production and reserve forecast.
- Facilities requirement.
- Economic optimization.
- Management approval.
- Implementation:
- Start with a plan of action, involving all functions.
- Flexible plan.
- Management support.
- Commitment of field personal.
- Periodic review meeting, involving all team members.
- Monitoring.
- Evaluation.
- Completing.
- Reasons of Failure Of Reservoir Management:
- Un-integrated system.
- Starting too late.
- Lack of maintenance.
- Having multiple bosses.
5. Data non-continuity & unreliability.
Data Management
Throughout the life of a reservoir, from exploration to abandonment, an enormous amount of data are collected. An efficient data management program consisting of acquisition, analysis, validating, storing, and retrieving plays a key role in reservoir management.
List of data types in reservoir simulation process:
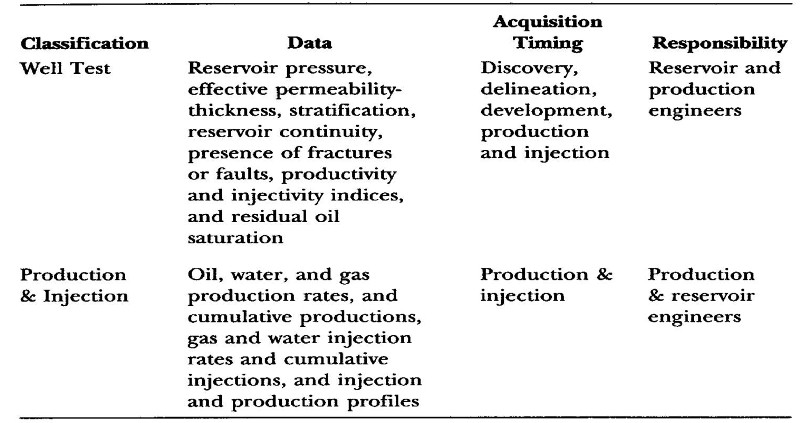
Two models are considered to have a data sharing relationship if they share a portion of their model data. For example, two models might share the same historical production data and well completion data. Data sharing relationships are very common among reservoir simulation models. However, data sharing among simulation models results in data replicas. The complete data of a model are typically stored in a repository managed by traditional approaches. If part of a model is shared by multiple models, multiple replicas of the data are created and distributed in each of those models.


These data replicas cause two problems to the repository. The first is concerned with the storage efficiency. The second is related to data consistency among the models with shared data components. In an oilfield asset, reservoir simulation models are regularly updated or calibrated as historical production data of the reservoir become available (the process is called history matching in petroleum engineering). Due to the complexity of a reservoir simulation model, propagating changes in these models properly and efficiently is a nontrivial task. Therefore, reducing data replicas in the repository is desirable in the management of reservoir simulation models.
Data replication has been studied extensively in the area of distributed systems. Previous research efforts can be classified into two categories. The first category focuses on data replication across a distributed system to improve reliability, fault-tolerance, or accessibility of the system. The second category addresses data consistency resulting from data replication. Replica consistency techniques and systems have been developed for this purpose. However, to the best of our knowledge, no existing work has addressed the data replica problem in the management of simulation models.
Reasons of Failure
- Un-integrated systems.
- Starting too late.
- Lack of maintenance.
- Having multiple bosses.
- Data non-continuity and unreliability.
References
- Integrated Petroleum Reservoir Management Abdus Satter, Ph.D. ,Research Consultant , Texaco E&P Technology Department , Houston, Texas / Ganesh C. Thakur, Ph.D. , Manager-Reservoir Simulation Division , Chevron Petroleum Technology Company , La Habra, California.
- Applying Optimization Technology in Reservoir Management
Vasantharajan, Optimal Decisions Inc.; R. Al-Hussainy, Amerada Hess Ltd.; and R.F. Heinemann, Berry
Petroleum Co.
- A simulation and data analysis system for large-scale, data-driven oil reservoir simulation studies, Pract. Exper. 2005; 17:1441–1467, Tahsin Kurc1,†, Umit Catalyurek1, Xi Zhang1, Joel Saltz1, Ryan Martino2, Mary Wheeler2, Małgorzata Peszy´nska3.

